Evaluating Search Relevance Using a Gold Standard Retrieval Dataset
Author: Jo Kristian Bergum from Vespa.ai blog Link: https://blog.vespa.ai/improving-retrieval-with-llm-as-a-judge/
Key Idea
- The post discusses how to create a reusable retrieval evaluation dataset using LLMs as judges, specifically for improving search relevance
- This dataset can be used to :
- Enable offline evaluation to compare the relevance results of different ranking methods (e.g., answering questions like: “Will Cohere embeddings perform better than the current search algorithm?“)
- Serve as a training set for machine learning algorithms, such as LTR
- Enable the reporting of “Relevance” as a metric
- Identify opportunities for improvement in the current ranking algorithm
Method
The author used https://search.vespa.ai as a simplified example to generate the retrieval dataset.
- *Step 1: Sample the Queries
- Most TREC query sets have < 100 queries, which is a fair number to start with
- The author uses 386 queries (unique queries in the last month)
- See more discussion on Query Sampling Strategy
- *Step 2: Sample Documents for each Query :
- Apply simple ranking algorithms(e.g. bm25 or production algorithm) to collect sample documents. This is also known as pooling in IR evaluations.
- Use multiple ranking algorithms to avoid bias from a specific algorithm.
- The author uses the top 10 results from 6 different ranking method (bm25, embeddings, 3 different kind of hybrid ranking, cross-encodes).
- On average, 26 documents are sampled for each query
- *Step 3: Define Judging Rules and Evaluation Metrics
- Use the relevancy triplets: highly relevant = 2, relevant = 1, and irrelevant = 0
- Metrics considered:
- Precision @ K, Recall @ K
- nDCG @K
- *Step 4: Evaluate the Prompt for _LLM as Judge
- The authors use a subset of queries and documents to evaluate the effectiveness of the “LLM as judge” prompt:
- Subset contains 26 queries with 3 documents each
- Collecting human judgements
- human spend ~ 1 hour 26 * 3 = ~ 90 query document pair with relevancy triplets.
- Collect LLM judgements
- use GPT4o to judge the same. See prompt in original article which applied few-shot prompting technique
- Comparison of human and LLM results (showing promising alignment):
- Direct comparison: Only 2 out of 90 judgments differed > 1 relevancy level
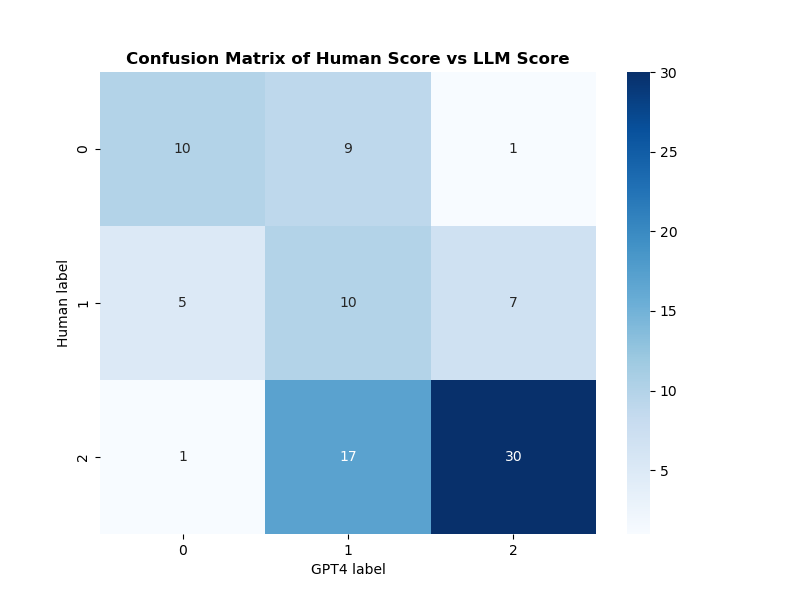
- nDCG comparison: use different ranking algorithm to calculate nDCG score using both human and LLM judgement. 0.97 correlation across ranking algorithms
- Direct comparison: Only 2 out of 90 judgments differed > 1 relevancy level
- The authors use a subset of queries and documents to evaluate the effectiveness of the “LLM as judge” prompt:
- *Step 5: Create the Gold Standard Dataset for Relevancy Evaluation
- Repeat Step 4 with the entire query and document samples:
- Query Dataset: use 386 queries
- Document Set: Use top 10 results of 6 different ranking methods (BM25, cosine-similarity, hybrid1, 2, 3, cross)
- In total: Evaluate 10K unique query-document pairs
- Generate the judgment list result using the LLM prompt from Step 4
- Repeat Step 4 with the entire query and document samples:
- Step 6: Evaluate Ranking Methods with gold standard dataset
- With the golden standard dataset, we can now evaluate different ranking algorithms using the following metrics:
- Primary metrics: nDCG@10
- Guardrail metrics: Judged@10: to see if all top 10 results are judged and identify any holes in the evaluation
- This dataset can also be used to evaluate learning-to-rank models. If we choose to do so, we should have another test set to evaluate the results.
- With the golden standard dataset, we can now evaluate different ranking algorithms using the following metrics:
Discussion:
- Query Sampling Strategy:
- For most search websites, we will likely need a more aggressive sampling strategy to ensure representative query coverage
- We could take a stratified sampling based on query frequency, seasonality, or product categories
- Include head, torso, tail queries. (OR Head queries might be sufficient for optimizing high-traffic scenarios)
- Incorporate product-driven or domain-specific query types (e.g. company specific terms)
- For most search websites, we will likely need a more aggressive sampling strategy to ensure representative query coverage
- For most production systems, we already have implicit feedback and user interactions (like clicks, skips). How can we use these results to improve the judgment list? Or should we? Are there bias concerns from historical data?